Science · Code · Curiosity

Word frequency analysis
In the previous update, I wrote about an analysis of single characters in Chinese text. I have now updated my program to analyse words instead of individual characters by searching the open source Chinese-English dictionary, CC-CEDICT, and checking whether combinations of characters form words. This slows program significantly and leads to a problem with names, most of which aren’t in the dictionary. However, speed yet isn't too much of an issue and I’ve created a way to output the information, so that once the analyser has been run once, I can save the information. The I can quickly load it in other programs that make use of it. I think I’ll get around the problem of names by having a dictionary of my own that the program checks first. This should also speed up analysis as this dictionary will only contain common words and will be much smaller, thus quicker to search.
I have run the program again, on a slightly larger dataset (just over 50,00 words, but I haven’t counted how many individual characters this represents) as the number of texts I have slowly increases. The analysis doesn’t differ too much from before, only it removes some of the redundancy of, for example, having 什 and 么 separate. It also reduces the frequency of certain words, such as 我 and 的, as 我的, 我们 and 他的 are counted as separate words. I think the main benefit will come when I add word types (noun, verb, adjective etc.).
This is a screenshot of the app with 发现 selected. In the lists you can see various other compound words, such as 不知道. You can also see that I’ve added the pinyin and meaning of the selected word, although I need to tidy up how this is displayed. I’d also like to add a search bar, so you can find specific words (it took me a while to find 发现). I’ve tried to add a better font (cyberbit.ttf), but for some reason, it has only replaced some characters (characters for which there is an alternative traditional character, I think). In fact, the same happens regardless of the font I used in Tkinter. Something to sort out later. I have at least sorted the problem in Pygame, but more on that later.
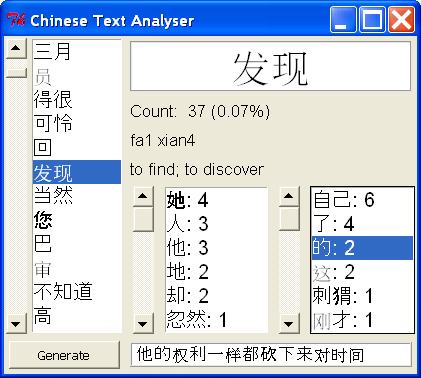
You can see that the app also now contains a Generate button and a box of gibberish. I'll explain the meaning of this in the next update.
Leave a comment
Comments are moderated and will appear after approval.