Science · Code · Curiosity

Making Markov chains
The most recent function I've added to my app is the ability to generate random sentences using the statistical patterns seen in the text. The program makes a note of the frequency of words that start clauses, picks one based on these probabilities, then next a word based on what words are likely to follow that one, and so on. Basically, the program constructs a Markov chain and uses this to generate a sentence; it’s what some spammers do to try and get around email filters. This is what can be seen at the bottom of the app shown the previous update.
Here are some example sentences, which range from the passable (e.g. sentence 1: “French people are also good”) to the gibberish:
- 法国人也很好
- 我要爱护地球环境很友好
- 这个问题
- 小王月文
- 她的机会来了电话号码
- 音乐家没有时间延长了
- 他们有五十六岁
- 长城
- 她想三月去逛街
- 这里出车祸了
After that, I decided I wanted better, more visual way to view the network. I tried sketching out a few networks, but the problem is things rapidly get messy and it’s difficult to get the layout right. This is a problem I’ve had before when trying to view a network I generated for a Go AI (which I’ll have to write about some time). To solve this problem and the Go AI network, I got the problem to solve itself spontaneously, by creating a physics simulation.
The program is adapted from my molecular dynamics simulation described here. It works by having every particle repel every other particle and having every bond, or interaction between particles contract to an certain length. Once the parameters have been played with, things are left to bounce about and after a short period of time, everything is nicely spread out. Sometimes, there can be problems if there are lots of loops in the network, but giving things a shake normally sorts things out. Shaking the network slightly makes it move in an pleasingly physical, jelly-like way.
The graph is centred on the word 这些, which happens to be the 32nd most common starting word in my analysis. Then I looked at the five most frequent words following it, and the five most frequent words following each of them (for 水平 and 花 there were fewer than five following words). The graph is built up with a recursive function which I’m quite pleased with, because I so really use recursion in my programs. It means I can increase the depth of the graph easily, but the image rapidly fills up and the program slows.
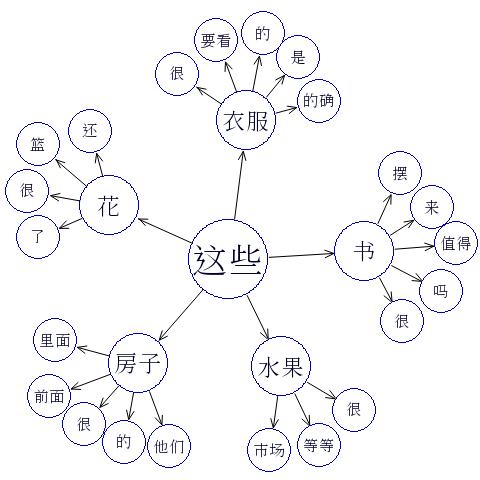
I still need to add the ability to create cross links. For example, there are are actually five bubbles containing the word 很 in the image, and these should be replaced by a single one with five inputs. It could be argued that the image is clearer with separate bubbles, which may turn out to be the case. However, it took me quite a long time to realise that there are five 很 (and two 的) bubbles in the current image, and it’s quite an interesting point. I think the reason for all the 很s is that 这些 is likely to be followed by a noun (the image shows us that the five most common words following 这些 are all nouns), and nouns are often followed by 很.
This also highlights why it will be useful to add the word categories (such as noun). The image also highlights a problem with this approach: 了 frequently follows 花, which is because 花 can be a verb as well as a noun (e.g. in the sentence 我今天花了很多钱, which is in my analysis). Any attempt to categories words will have to deal with words that have multiple functions.
I've found a similar sort of analysis of The Iliad here. Maybe I'll create a Java applet so people can interact with the networks.
Leave a comment
Comments are moderated and will appear after approval.