Science · Code · Curiosity

Character frequency analysis
As a start to a dictionary that might one day learn Chinese, I created a little program that analyses the frequency of characters in a collection of texts. Currently, I have over 50,000 characters worth of text, which includes about 2000 different characters. My analyser program started off simply counting how often each of the characters occurs in these sample texts. This should help me identify which characters are most common and so best to learn. The program found that the most common character in the texts I've collected is 的, which makes up 3.1% of the characters. According to A Key to Chinese Speech and Writing, 的 is the most common character in Chinese and makes up about 4% of text; I’m not sure why it is less common in my text, but I suspect it’s because 的 occurs more often in more complex sentences.
In my text, the most common characters are 的, 了, 我, 一, 是, 不, 这, and 他.
A Key to Chinese Speech and Writing states that the most common characters are 的, 一, 了, 是, 不, 我, 在, 有 and 人 in that order. My analysis may be skewed by Alice in Wonderland (from nciku, and a translation I bought in China), which currently makes up the bulk of my text. The result is in a glut of ‘Ailisi’, Red Queens and Cheshire cats. The other sentences are from iKnow courses and various study books, so are generally quite simple, which is probably why the pronouns and 这 are more common than normal.
Preceding and proceeding
I then expanded the analysis to count the frequency of characters before and after each of those in the text. I hope this will help me to learn how characters are most commonly used. For example, I first learnt that 发 means 'hair or 'to emit'; my program shows that ~45% of the time, 发 is part of the word 发现 or 发生 (meaning 'to discover' and 'to occur' respectively). I think that learning these meanings is probably a better strategy than trying to learn what the character means by itself.
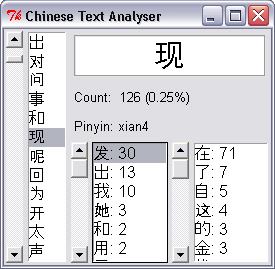
One difficulty at the moment is it’s not possible to know whether the character in question actually forms a word with previous or following characters. However, if the combination of characters is very common, then it may not really matter. For example, 我 is followed by 的 about 10% of the time, and it probably doesn’t matter whether you consider 我的 as a word meaning 'my' or a common grammatical construction of 'me' + 'possessive'.
The next step in my program will be to combine characters into words (probably using a dictionary to check whether they are really words, or perhaps just joining frequently occurring pairs of characters). I can then see which words are the most common and what words border them. However, I foresee a potential problem with overlapping words, or words made up of more than two characters.
Another feature that I’d like to add is the ability to group words into grammatical groups, such as pronouns, verbs, adjectives etc. (I hope to add this information to my Chinese reader too). I should then be able to identify grammatical patterns, such as which words tend to precede adjectives (很 and 真 for example). It would also identify patterns such as 们 always preceding a pronoun, though I’m not sure how to deal with this if 我们, 他们, 你们 etc. are viewed as single words. Maybe I’ll just look at sentences as both collections of single hanzi and as collections of words.
Comments 1
Leave a comment
Comments are moderated and will appear after approval.
Hello, I'm so glad to have found someone who not only had the idea but also the know-how to bring something like this into being! Well done! When I began to learn Chinese 10 years ago I had a source text that I wanted to be able to read in Chinese, but wished there was a way to funnel all the characters through a program like this, and tell me which were the most frequent characters (of that particular text), so as to focus my energies on learning just those, so as to be able to read the bulk of that text (I could always just hand-write pinyin over the very uncommon ones). I'm curious whether this analysis tool is available for the public?