Science · Code · Curiosity

Building hanzi trees
In the previous update, I showed how a physical simulation could be used to cluster hanzi. The clustering seen by that approach can be recapitulated using a more rigid and rigorous approach.
I have finally got a basic tree-generating and -drawing program to work. It uses a very simple algorithm: first it finds the smallest distance in the distance matrix, then it joins those hanzi into a cluster whose distance from the other hanzi is the average of the distances to each of its components. When new branches are added to a cluster, clusters are arranged to minimise the distance between neighbouring hanzi on the two branches (it’s hard to explain and even harder to code).
The algorithm is based on an explanation in An Introduction to Bioinformatic Algorithms, which has goes on to explain more complex methods. It also explains a lot of algorithms for search sequences for patterns, which I might try to use on Chinese.
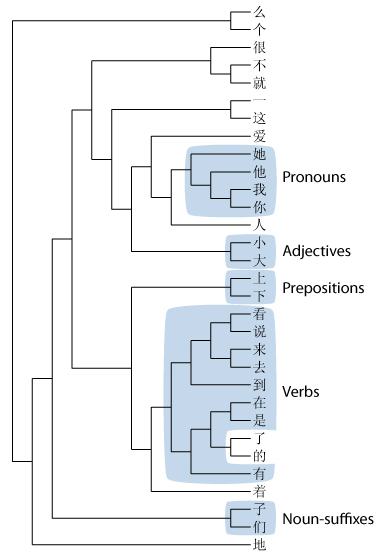
The tree shown is based on the same selection of characters as used before. Like the physical clustering, the tree shows how the pronouns, adjectives, prepositions and verbs form distinct clusters (I’ve excluded 着 from the verbs because it more often used as a verb ending, but it forms an out-shoot of the verb group, perhaps because of its dual role). The characters 个, 么 and 地 again form out-groups. Interestingly, 子 and 们 also cluster, and both are used to suffix nouns. Also, 了 and 的 are found within the verb group, which makes sense as they often suffix verbs so will be followed by the same sort of words that follow verbs (e.g. you can say both 我喝一杯茶 and 我喝了一杯茶). It’s also interesting to see how the verb group breaks down: the verbs of movement, 去 with 来, the verbs of being 是 with 在, and the verbs of sensing, 看 with 说, though maybe this is coincidental. We can find explanations for 一 and 这 forming a group (they are often followed by measure words and form the subject of a sentence), and for 就, 不 and 很 (adverbs that come before verbs).
In conclusion, the simple distance function I created seems to give a reasonable measure of the relationship between hanzi.
Using this distance function might therefore be used to predict the role of a word in a sentence. Think the approach could be improved when I have a measure of how often a character follows verbs in general. I wonder now whether I could avoid having to class the words as verbs, nouns etc., and get the program to build its own categories and then feed this information back into the system to improve it. For example, building this tree, the program could, with some degree of certainty, decide that 我, 他, 你 and 她 form a group and then calculate how often other characters are preceded and proceeded by this group.
Expanding the tree
If I extend the tree to contain all characters with a frequency of more than 0.04%, then the new characters fit nicely into the same groups. The tree can be split into two major groups, which I call the noun-type and verb-type groups.
The noun-type group (in blue) contains the nouns and words connected with nouns, such as the suffixes 们 and 子; the determiners, 那 and 这; the prepositions, 上 and 下; and the adjectives.
The verb-type group (in green) contains the verbs and adverbs. In addition, there are some outliers which are found in very specific contexts. For example, 么 is only found after 什, 这, 那 or 怎; 丽 and 丝 are almost exclusively only found in the name Alice (in my texts at least).
N.B. I made a small change to the way the tree is displayed such that the branch lengths are proportion to the distances between characters, although the tree is still ultrametric (so all the leaves line up).
Leave a comment
Comments are moderated and will appear after approval.